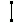Building a tiny fully local AI agent desk toy

My initial experience with large language models began in 2023, when OpenAI introduced their APIs and I integrated them into my personal Telegram bot. I remember the excitement of using custom commands to trigger pieces of code on my Raspberry Pi, and it felt like pure magic. However, as the months went by, the excitement quickly faded when I looked at my bank account after making a bunch of requests.
These days using Gen AI feels almost retro, like working on a time-sharing terminal from the '60s. Even though external services are more powerful and can offload heavy computation, local inference feels much more appealing and futuristic to me than relying on a provider that will probably store all my conversations and data for who knows what purpose.
So many things have come out since 2023, like new quantization techniques, structured output, tools, and the gradual emergence and a new definition of Agents. Running LLMs on a Raspberry Pi was nearly impossible two years ago, but about four months ago I asked myself, how hard could it be to build something fully local using state of the art open models and run them on small hardware like a Pi 5? So I embarked on this new journey of desperation and interesting hardware constraints...
Nothing leaves the Pi
My dream over the years has always been to recreate a completely offline AI assistant that can execute code just by listening to my spoken words. You might say, sure, but why not use something like Home Assistant? It's even in the name, duh! - But my answer would be: because I wanted to learn how to build this entirely from scratch and I also wanted to have some fun prototyping a hands free UI experience.
I started with a simple React Vite front end that communicated with a Sinatra back end to start and stop recording from the physical microphone. The backend then transcribed the WAV file using an excellent reimplementation of OpenAI's Whisper called faster-whisper. The transcriber runs as an external web service in the background with faster-whisper loaded at startup. I then introduced a wake word mechanism using Vosk in a Python script, which runs only when the app is in "standby" mode and is terminated when the LLM is running, so it does not compete for CPU resources. Since my rec command stops recording automatically when the user stops speaking into the microphone, Sinatra then notifies the frontend via WebSocket, making real-time communication very straightforward.
Finally, for managing the language models I've used Ollama, because it was a no-brainer to install and to use their APIs. I am aware of their shady practices and the feud with the creator of llama.cpp. Eventually I will migrate, but for now it has served its purpose for rapidly prototyping my project.
The whole stack was designed to be fully local from the start. Sure, you could invoke tools to query online APIs, but that would be up to the user.
Update 9/3/2026
The backend layer has now been rewritten in Express.js and the project no longer needs Ruby as a dependency.
Text to command
My initial PoC was a continuation of the Joshua Bot structure, where the first step involved the text-to-command interpreter model recognizing commands starting with a slash (e.g. /lights on) and then provided the raw output directly to the user. The natural progression for me was to move to a different approach, where the first model would produce an output after executing a command, and this output would then be fed to a second conversational model for processing (more on that later).
This initial MVP was useful for developing the basic hands-free interaction and prototyping the UI. It was barely functional, though. I still struggled to get the first model to understand the slash command notation with all the parameters, and there was always a 50/50 chance that the model would return the correct command. Then I realized, wait, why don't I use structured output? That's exactly what it's meant for!
I defined a pretty simple JSON shape:
format: {
type: "object",
properties: {
function: { type: "string" },
describe: { type: "string" },
parameter: { type: "string" }
},
required: ["function", "describe", "parameter"]
}
so the model would respond with something like:
{
"function": "sendEmail",
"describe": "I'm sending an email...",
"parameter": "The weather in Dublin is spitting rain"
}
After implementing structured outputs, I was able to eliminate the need for awkward parsing logic with the slash command notation, and the model returned the payload correctly. At last, I could invoke functions and execute commands reliably!
Make it agentic
So far, my project behaved just like a normal chatbot, which means:
ask question → perform single action → show results
I started researching the definition of an agentic AI and stumbled upon this one. Great, I thought, I had a lead for my next goal: how about using tools in a while loop? After experimenting for a few days, it proved to be incredibly resource-intensive for a Raspberry Pi. Using tools with models such as Qwen3 requires a reasoning phase before starting the actual tool-chain invocation. Now don't get me wrong, on a Raspberry Pi this is certainly feasible, but the whole process could take four to five minutes for several tool calls.
I did not like that!
Here's the problem I wanted to solve:
- The model had to invoke a sequence of functions with dynamic parameters.
- I wanted the model to describe what it was doing while executing the tool, but for some reason, this proved difficult for small models to return both a tool call and a message simultaneously.
- It had to be done within a reasonable time span, ideally no more than two minutes.
So, perhaps this is not the most elegant solution, but after a long period of extensive testing, here's how I solved it:
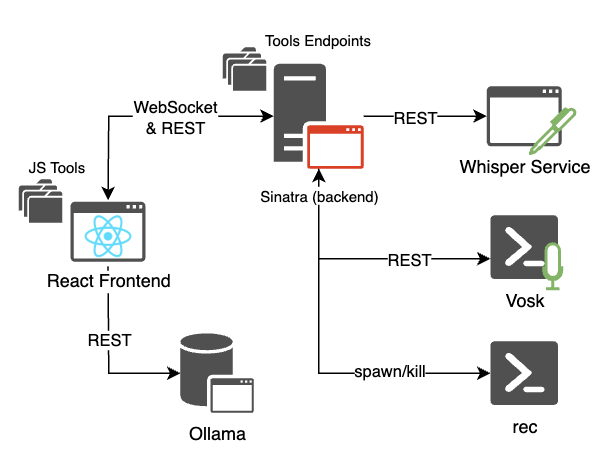
I used Qwen3 1.7b with reasoning switched off. Then I placed everything inside a loop that would run five times, just to ensure the model would not get stuck running indefinitely. The prompt asks the model to break down the user request into a sequence of function calls. The model had to respect both the structure of the JSON (explained earlier) and the chronological order of tasks expressed by the user. Finally, I injected the list of available functions directly into the system prompt so that the model would be aware of which tools were available to use.
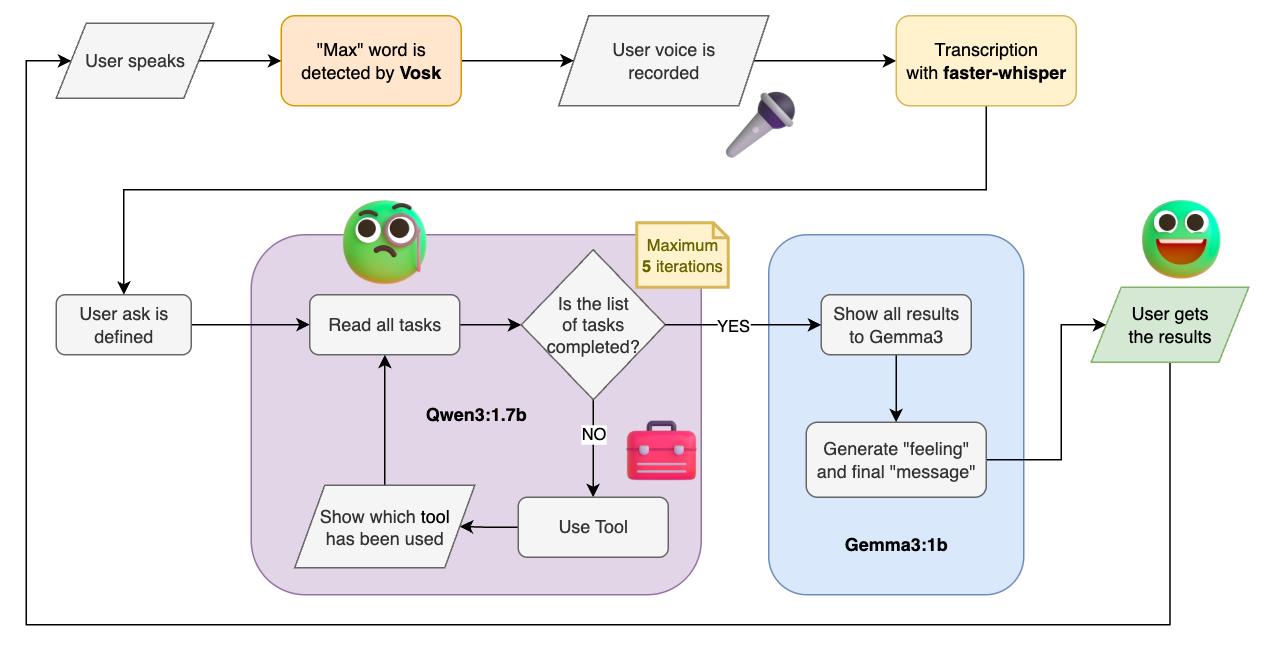 (Final flow chart of the project)
(Final flow chart of the project)
After wrapping everything up, I was surprised to see that, using this new prompt, the model would correctly execute the list of tasks in the right order. When a tool produced an output, it would then be fed to the next tool call until the user task was completed.
globalAgentChatRef.current.push({
role: 'user',
content: `Task ${toolLoopGuardCount} - function "${functionName}", result: "${toolResult}". If the list of tasks I've asked is finished call finished(), otherwise continue calling a new function...`
});
Again, all of this was achieved without a reasoning model or actual tool-call APIs. I would love to be proven wrong, though, if you have found a better and more efficient way to solve my original problems, give me a shout!
Caveats
After stress-testing the agent, I noticed that I could perform four to five sequences of function calls, but beyond that, the model would start to hallucinate most of the time, especially when executing the last actions. Switching to a more capable model or a reasoning one would obviously improve the overall experience, but at the cost of significantly slower performance.
I also noticed that introducing different "roles" in a conversation, such as system or tool, would make the calls slower. So I tweaked all the prompts so that the conversation occurred only between user and assistant. I know it's not elegant, but it worked!
Tools
Creating tools is as simple as making a JavaScript module that exports an object with four properties: the tool's name, the parameters passed to the function, a describe field, and the function's main execution body. These modules are dynamically imported into the app during the startup phase and injected into the system prompt as mentioned earlier. The parameter definition is not as precise as in the official Tools APIs of course; it might require some examples in the description field for the model to understand its usage.
Hey Simon Willison, if you're reading, it cannot be called an "agent" if it doesn't have full root shell access...
import config from '../config.js';
const name = 'shell';
const params = 'shellCommand';
const description = 'executes a shell command in the terminal and gives back the result';
const execution = async (parameter) => {
const backendResponse = await fetch(`${config.BACKEND_URL}/shell`, {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ command: parameter }),
});
if (!backendResponse.ok) {
throw new Error(`HTTP error! status: ${backendResponse.status}`);
}
const commandOutput = await backendResponse.json();
const outputText = commandOutput.message;
return `Output for "${parameter}": "${outputText}".`;
};
export default { name, params, description, execution };
/s
Emotions
If you've read this far, you might be asking yourself why I used two models instead of getting the conversational reply directly from the first one. The reason is that I wanted to try a small experiment: producing an output from the second model (in my case Gemma3:1b) that would also attach a "feeling" along with the reply text.
The "feeling" would essentially be an array of emotions that the model could choose from immediately after generating the response text, e.g. laugh, happy, sad, interested, bored, etc. Using structured output once again came in handy, as I could simply devise a payload in the following format:
format: {
type: "object",
properties: {
message: {
type: "string"
},
feeling: {
type: "string",
enum: [
"laugh",
"happy",
"interested",
"sad",
"confused",
...
]
}
},
required: [
"message",
"feeling"
]
}
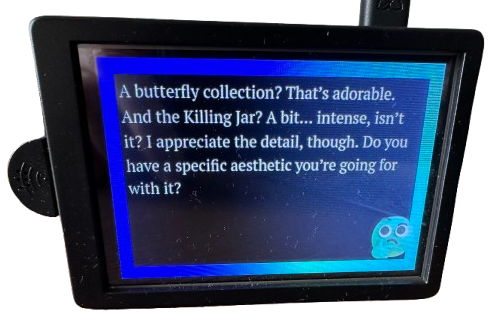
In practical terms, this emotion would be associated with an emoji image displayed in the corner of the screen along with the output text.
Here's me having fun, performing a little Voight-Kampff test from the movie Blade Runner (1982) to see if different emotions would be triggered, and I have to say, I was not disappointed:


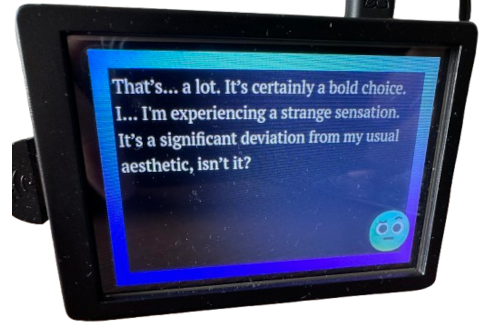
To complicate things even more, I also wanted to stream the response of the conversational model.
The main challenge I had to overcome was interpreting the JSON correctly as it was streamed by the APIs. I came up with a very flaky but somewhat functional JSON parser that would display the text on screen as soon as the message segment was detected, and finally, when the feeling value was chosen, it would be displayed in the corner.
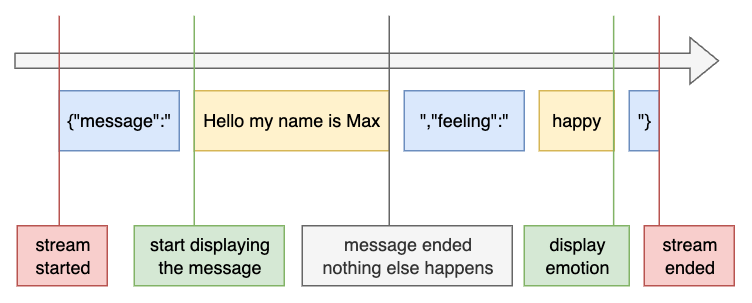
The reason I placed the feeling at the very end, after the message part, was so that the stream handler could display the main messages as quickly as possible and save some time. Another idea was that the model would generate the message naturally, without being influenced by a feeling generated beforehand, as the earliest tokens strongly influence the trajectory of the response. So the message content forms first, and the appended feeling acts more like metadata than a guiding context.
The UI
The software and user experience were designed from the very beginning on a Raspberry Pi 5 that I had lying around my house. While building the project I also found online a nice compact case that could accommodate a small display and a fan. I really liked the form factor and tried to minimize clutter and distractions in the UI to make the experience as smooth as possible.
The interface was designed to be very simple. A blue rotating ribbon (or no ribbon at all when in standby mode) around the head of the character indicates that the app is ready to receive the wake word. A red pulsating ribbon means your voice is being recorded, and a final rainbow ribbon indicates that the LLM is running and doing its thing!
Alternatively, you can tap the screen instead of using the wake word to start recording, and tap it again to stop. The tap can also be used to interrupt the LLM while it is generating the final response.
The green smiley face on screen was made with Microsoft's Fluent Emojis; I simply edited some emoji in GIMP.
Here's a little demo:
Based on my tests, a chain of about three function calls took roughly 1 minute and 30 seconds for the LLM to return the final message. Naturally, if a tool produced a large output (such as the Wikipedia tool I included in the repo), the response time would be longer. With four to five calls, the process took just over 2 minutes. Overall, I decided that I could settle for that!
Oh and yes, I named it Max Headbox as an honorable reference to Max Headroom!
Final considerations
Over the past few months, I familiarized myself with a ton of open models. Ultimately, I ended up using Qwen3 1.7b for the agentic model and Gemma3 1b for the conversational model. Anything above 3b parameters felt quite impractical for a Raspberry Pi unfortunately. During development, I also came across this interesting article which turned out to be quite accurate. Qwen2.5 3b definitely performed better and hallucinated less but took a few seconds longer to run compared to the 1b, for obvious reasons. I was also very impressed by Gemma2 2b, which I highly recommend as an alternative for the conversational model. I really think Alibaba and Google deserve credit for releasing such excellent small models.
To conclude, I have to say this project was incredibly fun to work on, frustrating at times but certainly worth sharing. While I didn't intend to create anything serious (it's just a toy, after all!), it gave me some insight into how AI agents work, and I learned something along the way. Perhaps the technology and architecture will change in six months, and I'll have to start all over again. Go figure!
I understand that many people are concerned, tired and overloaded by AI. I'm mindful of its environmental impact and strongly oppose its use for generating so-called "art". Though I can't help but think that if someone with a time machine had given me this box back during COVID, I probably would have been astonished by what it could do.